
Data sharding is an effective solution to deal with massive data storage and computation.
Pisanix, a database mesh solution sponsored by SphereEx, now provides data sharding governance capability based on the underlying database - allowing users to scale out computing and storage.
Starting from v0.3.0, Pisanix will gradually support data sharding, with this release supporting single database sharding.
1. Introducing data sharding
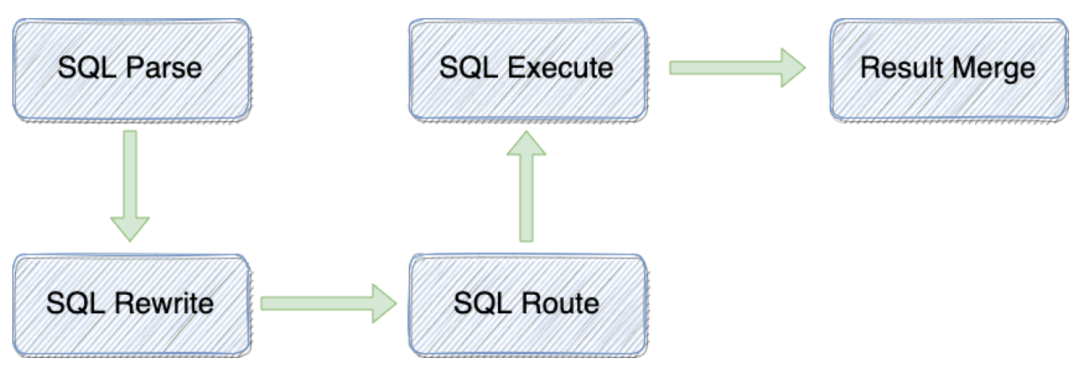
As shown in Figure 1 below, data sharding mainly consists of SQL parse, SQL rewriting, SQL route, SQL execution, and result merge.
Concepts:
SQL Parse: During the sharding process, once the request is received by Pisa-Proxy, it will first go through SQL Parser, and the SQL will be parsed into AST. SQL Rewriting: After parsing, Pisa-Proxy will rewrite the current SQL statement according to the sharding rules to generate the real SQL statement to be executed. SQL Route: Pisa-Proxy routes the rewritten SQL statements to the corresponding data source at the backend to execute the SQL statements according to the sharding rules. SQL Execution: Pisa-Proxy will rewrite the SQL statement and push it down to the back-end real database for execution. Result Merge: Pisa-Proxy merges the query results and returns them to the client.
Introducing SQL Rewriting
SQL rewriting is a critical module in data sharding. Pisa-Proxy needs to rewrite the current SQL statement according to the sharding rules to generate the real SQL statement to be executed. SQL rewriting can be of the following types:
Identifier Rewriting
Identifiers to be rewritten include table names, index names, and schema names.
Table name rewriting means the process of finding the location of a logical table in the original SQL and rewriting it to a real table. Table name rewriting is a typical scenario that requires parsing of SQL. For example, if the logical SQL is:
SELECT order_id FROM order.t_order WHERE order_id = 1;
Suppose that the shard key of this table is order_id and order_id=1, and the number of sharding is specified as two, then the SQL statement would be as follows:
SELECT order_id FROM order.t_order_00001 WHERE order_id = 1;
The following figure shows the data query process:
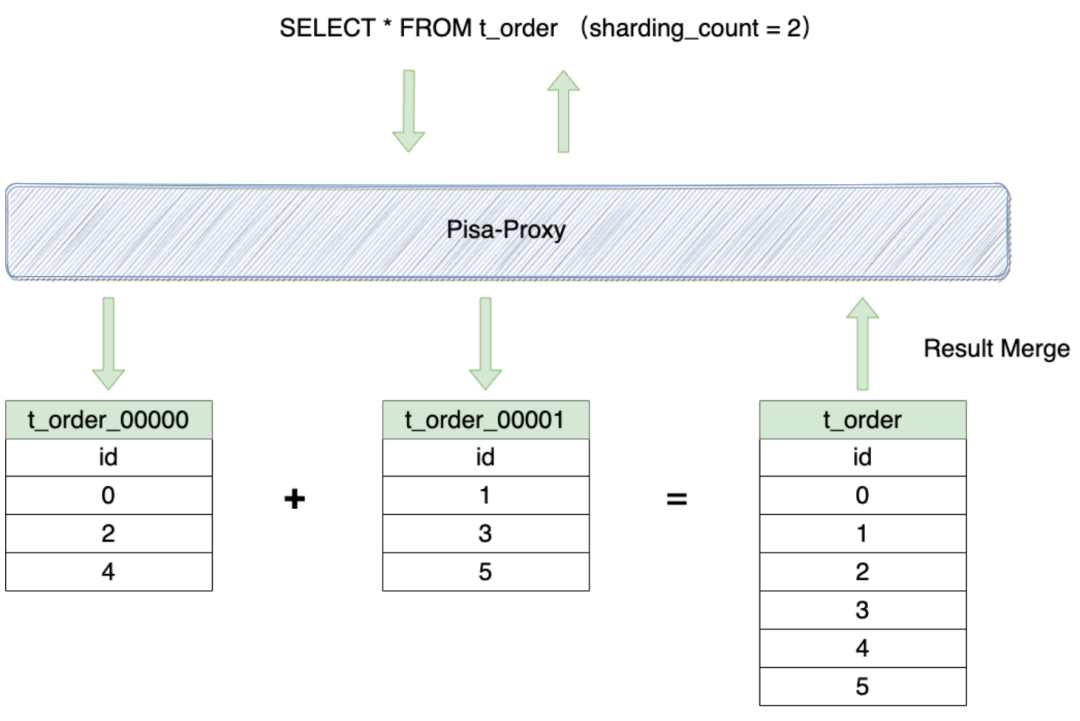
Taking data writing as an example, the data insertion process is as follows:
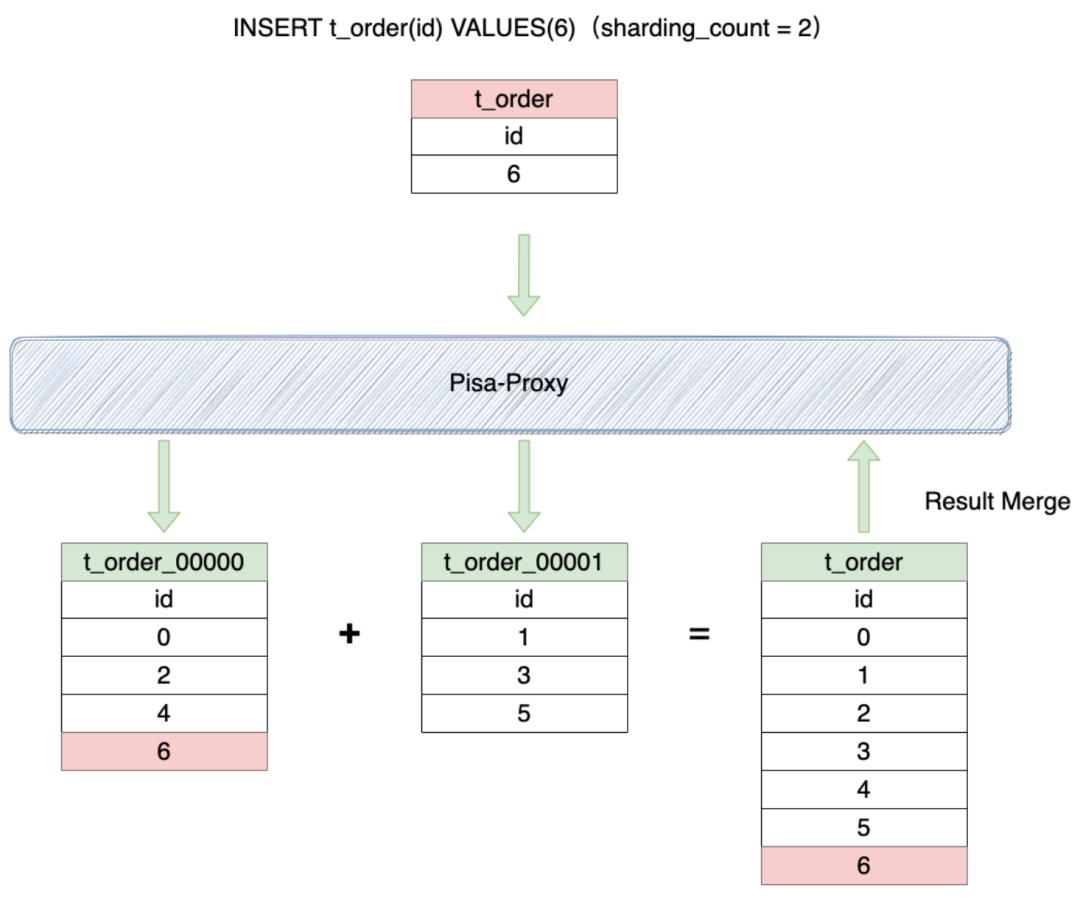
Note: When the SQL rewriting process modifies the identifier to calculate the real table name, it will automatically add the table index according to the sharding rule. The index rule is table name_index, and the index bit is five. For example, the t_order table is overwritten to t_order_00000. Therefore, you need to create the corresponding table name based on the actual business scenario.
Column Supplement Rewriting
There are two cases that need supplement columns in a query statement. In the first case, Pisa-Proxy needs to get the data during the result merge, but the data is not returned by the queried SQL.
In this case, it mainly applies to GROUP BY and ORDER BY. When merging the results, you need to group and order the field items according to GROUP BY and ORDER BY, but if the original SQL does not contain grouping or ordering items in the selections, you need to rewrite the original SQL.
For instance, with an instance with the following SQL statement:
SELECT order_id, user_id FROM t_order ORDER BY user_id;
Since user_id is used for sorting, the data of user_id needs to be retrieved in the result merge, the above SQL statement contains the data of user_id, so there is no need to add columns, and modifying the identifier is enough.
SELECT order_id FROM t_order ORDER BY user_id;
This SQL depends on the user_id for sorting. Therefore, the column must be supplemented. The rewritten SQL is as follows:
SELECT order_id, user_id AS USER_ID_ORDER_BY_DERIVED_00000 FROM t_order_00000 ORDER BY user_id;
The second case of column supplement is the use of AVG aggregate functions.
In distributed scenarios, using (avg1 + avg2 + avg3)/3 to calculate the average is incorrect and should be rewritten as (sum1 + sum2 + sum3) /(count1 + count2 + count3).
In this case, rewriting the SQL containing AVG to SUM and COUNT is required, and recalculating the average when the results are merged. For example:
SELECT AVG(price) FROM t_order WHERE user_id = 1;
The rewritten SQL is as follows:
SELECT COUNT(price) AS AVG_DERIVED_COUNT_00000, SUM(price) AS AVG_DERIVED_SUM_00000 FROM t_order_00000 WHERE user_id = 1;
Configuration Description
This release supports query, update, deletion, and modification of the single database sharding based on a single shard key. The configuration items are as follows:
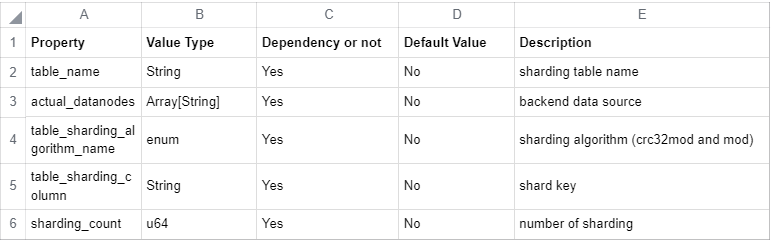
Note: The broadcast table, binding table, sub-query, table sharding, distributed rules based on expressions, distributed transaction, and cross-database Join will be gradually supported in later versions.
Taking the scenario in Figure 2 and Figure 3 as an example, its corresponding CRD configuration is as follows:
# Declare a VirtualDatabase as a logical database apiVersion: core.database-mesh.io/v1alpha1 kind: VirtualDatabase metadata: name: test namespace: default spec: services: - databaseMySQL: db: test host: 127.0.0.1 password: "root" port: 3306 user: root name: mysql trafficStrategy: test dataShard: test --- # Declare TrafficStrategy the specified proxy apiVersion: core.database-mesh.io/v1alpha1 kind: TrafficStrategy metadata: name: test namespace: default spec: loadBalance: simpleLoadBalance: kind: random selector: matchLabels: source: test --- # Declare DataShard the sharding rules apiVersion: core.database-mesh.io/v1alpha1 kind: DataShard metadata: name: test namespace: default labels: source: test spec: rules: - tableName: "t_order" tableStrategy: tableShardingAlgorithmName: "mod" tableShardingColumn: "id" shardingCount: 2 actualDatanodes: valueSource: nodes: - value: "ds001" --- # Declare DatabaseEndpoint the identified physical database apiVersion: core.database-mesh.io/v1alpha1 kind: DatabaseEndpoint metadata: labels: source: test name: ds001 namespace: default spec: database: MySQL: db: test host: mysql.default password: root port: 3306 user: root
2. Pisanix v0.3.0 Overview
This release has been made possible thanks to 102 merged PRs by the following contributors:

New Features
- Pisa-Controller
- Support DataShard CRD #326
- Pisa-Proxy
- Support single database sharding #338
Enhancements
- Pisa-Controller
- Optimized Sidecar injection #234
- Support generic static read/write splitting rule #251
- Pisa-Proxy
- Support SHOW STATUS parser #254
- Introduce CloudWatch Sinker for later audit events #258
- Support CREATE TABLESPACE parser #259
- Support CREATE SERVER #261
- Front MySQL protocol uses tokio codec #263
- Support dynamic read/write splitting Monitor switch #264
- Refactor MySQL server runtime #274
- Experimental SIMD in SQL Parser #278
Fixes
- Pisa-Proxy
- Fix Apple M1 Macbook build failure in some cases #260
- Fix malformed SQL format in some cases #291
- Fix abnormal SQL parsing issues #297
- Fix unexpected AST in some cases #301
- Fix Pisa-Proxy crash without receiving VirtualDatabase configuration #319
Others
- Golang-SDK
- Move CRD and kubernetes client to github.com/database-mesh/golang-sdk #247
- Add DataShard CRD and update VirtualDatabase with DataShard as new spec member in Golang-SDK
- Docs
- Add sharding doc: https://www.pisanix.io/docs/Features/sharding
- Optimized microservices-demo deployment instruction #318
- Fork and optimize the code and configuration of github.com/microservices-demo/microservices-demo for a better demo. See: github.com/database-mesh/microservices-demo
- Charts
- Update controller and proxy mirror to v0.3.0
Known Issues
- DO NOT support SHOW DATABASES and SHOW TABLES
- DO NOT support observability under sharding mode
3. Community

Pisanix is an open source implementation of Database Mesh. It builds unified database governance based on Rust, and aims at providing four major development and application experiences: local database, unified configuration management, multi-protocol support, and cloud-native architecture.
The community is currently collecting more user scenarios and applications. If you've started or are planning to test Pisanix, please record it in the issue below.
The community will prioritize the development and optimization of features related to real scenarios.
The Pisanix community organizes an online meeting every two weeks. Here are the details to join:
- Mailing list
- Biweekly meeting - English community (from February 16, 2022), on Wednesday 9:00 AM PST
- Biweekly meeting - Chinese community (from April 27, 2022), on Wednesday 9:00 PM GMT+8
- Slack
- Meeting minutes
You're welcome to join us!
