
客户介绍
客户介绍:
【某全球汽车产业巨头】作为世界顶尖汽车品牌在华的核心分支机构,为数百万车主提供卓越的产品与服务。其业务体系庞大,覆盖了从研发、制造、营销到车联网服务的全价值链。在此过程中,其核心业务系统承载并处理着海量的车辆实时数据和车主个人敏感信息,日均处理高频、高并发的业务交互,对系统的稳定性与数据的安全性要求极为严苛。
应用介绍:
应用名称:车主实名认证系统/车联网数据中心/次世代呼叫中心
应用说明:三大系统协同支撑公司在华业务,分为车主实名认证、智能网联服务与全天候客户支持三大核心职能
业务挑战
客户需求:
为强化数据安全管理,需对三大核心业务系统涉及的敏感数据实施全量加密。系统中涉及车主身份、车辆状态、服务契约等敏感数据,加密旨在满足《数据安全法》等法规要求,保障数据在存储与传输过程中的保密性与完整性,同时维持业务系统的高可用性与实时性。
核心痛点:
项目的关键挑战在于安全加固必须在保障业务连续性的前提下进行。三大核心系统广泛依赖数据库内置函数(对敏感字段进行实时查询与业务逻辑处理。若采用传统加密方案导致密文数据无法参与运算,将意味着需要对大量核心业务逻辑进行重构,这不仅带来巨大的研发成本和时间投入,更会引入不可预知的业务风险,项目难度和成本呈指数级增长。
- 业务维度:要求加密过程对现有业务透明,实现平滑升级,零感知、零中断。
- 技术维度:需找到一种技术方案,能同时实现高强度加密和对加密数据的可计算能力。
解决方案
方案概述:
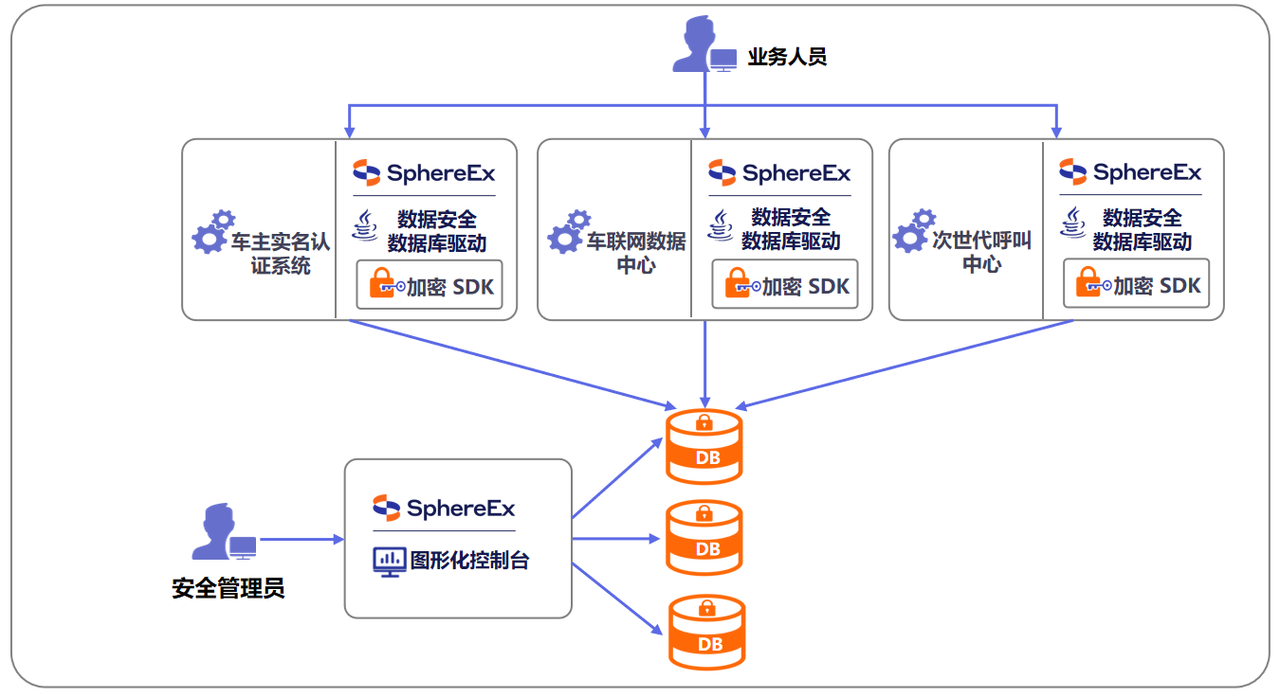
SphereEx 提供了以 “应用透明、密文可算” 为核心的数据安全解决方案,针对车主实名认证系统、车联网数据中心、次世代呼叫中心三大核心业务系统,通过在各系统中集成SphereEx数据安全数据库驱动及加密SDK,实现业务数据的加密存储;安全管理员借助SphereEx图形化控制台统一管理加密策略与配置,全面保障车企核心业务数据的存储安全与合规性。
架构图:
方案亮点
- 支持加密字段复杂运算:完美解决了客户的核心痛点。SphereEx 方案支持对加密存储的数据进行字符串拼接、截取、模糊匹配、变形等复杂函数运算,无需修改业务代码即可满足高频实时业务场景,实现了安全与效能的统一。
- 卓越的兼容性与灵活性:方案全面兼容复杂的数据库结构,如 PostgreSQL 的非 public schema,能够适应客户现有的、多样化的技术环境,降低了部署复杂度。
- 企业级安全管理:提供可视化的管理控制台,实现了加密策略、密钥生命周期的集中化、规范化管理,符合企业级安全治理的要求。
客户收益
核心成果:
- 安全覆盖度:成功对三大核心业务系统、【上百】个敏感字段实现了应用无损的加密改造。
- 业务连续性:业务系统性能波动小于【10】%,确保了高频实时业务的稳定运行,实现了业务零中断的平滑升级。
- 密态计算支持:实现加密数据的复杂运算,全面支持字符串处理、模糊匹配等高阶函数。成功解决了密文状态下业务查询与计算的技术难题。
战略价值:
- 筑牢合规防线:率先满足国家数据安全法规要求,建立了行业领先的数据安全合规实践,为企业在华业务的长期稳定发展扫清了合规障碍。
- 提升品牌信任度:通过技术手段切实保护了百万车主的隐私安全,极大增强了车主对品牌的信任感,提升了企业声誉和品牌价值。
- 构建安全底座:本次成功实践为企业未来的数据要素化利用(如数据分析和价值挖掘)奠定了坚实的安全基础,因为即使在数据被泄露的情况下,核心敏感信息仍处于加密状态,有效降低了数据泄露风险。
- 打造行业标杆:该项目的成功,为整个汽车行业在数字化转型过程中的数据安全保护提供了极具参考价值的范本。
