
客户介绍
客户介绍:
【某知名汽车品牌旗下金融租赁公司】客户是由某大型汽车集团控股的头部汽车金融租赁公司,专注于为个人与企业客户提供全面的汽车融资与租赁解决方案,资产管理规模与业务量位居行业前列。其核心的融资租赁系统,贯穿了从贷前审批、合同签订、贷中监控到贷后催收及资产处置的全业务流程,每日处理并存储着海量的个人身份信息、银行账户、征信报告、车辆信息等极度敏感的金融数据。数据安全与合规性是其业务的生命线。
应用介绍:
应用名称:融资租赁系统
应用说明:购车贷款业务管理,覆盖贷前审批、贷中监控至贷后催收及资产处置全流程。
业务挑战
客户需求:
在购车贷款业务的全流程管理过程中,需处理大量客户个人身份、车辆及交易等敏感数据,为满足《网络安全法》、《个人信息保护法》以及金融行业日益严格的数据合规要求,并防范内部外部数据泄露风险,公司急需对系统中的敏感数据进行加密存储。其核心需求是找到一个对现有复杂业务系统影响最小、无需大规模改造代码,且能保证业务连续性和系统稳定性的加密方案
核心痛点:
- 业务逻辑复杂,技术改造成本高: 融资租赁系统经过长期迭代,业务逻辑复杂,大量依赖视图和复杂的嵌套SQL查询进行数据分析和报表生成。任何需要修改SQL或应用代码的加密方案都将面临极高的技术风险和实施成本。
- 加密范围广,管理难度大: 需要加密的敏感数据散布在数百张业务表中,涉及上千个字段。如何统一、高效地管理如此大规模的加密策略,是一个巨大的运维挑战。
- 金融级业务连续性要求: 作为金融核心系统,必须保证7x24小时高可用性。加密方案必须稳定可靠,不能引入单点故障或显著性能延迟,以免影响正常的贷款审批和交易流程。
解决方案
方案概述:
融资租赁系统采用SphereEx数据安全网关解决方案实现数据加密保护。业务人员通过融资租赁系统发起的业务数据,经集成加密SDK的SphereEx数据安全网关加密后,存储至加密数据库;DBA通过SphereEx图形化控制台统一管理网关配置与加密策略,全程保障融资租赁业务敏感数据的传输与存储安全。
架构图:
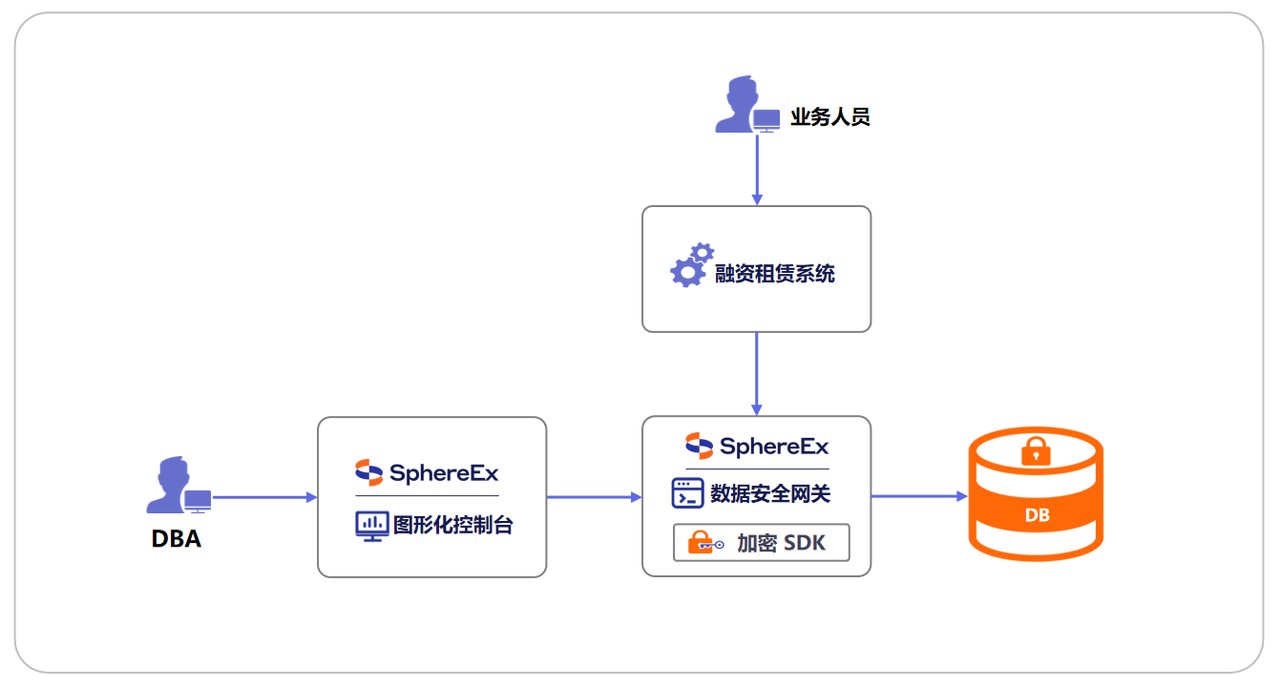
方案亮点
- 卓越的SQL兼容性: 方案核心优势在于对复杂SQL的全面兼容。无论是基于多张表的视图查询,还是包含子查询、关联查询的复杂嵌套SQL,数据安全网关都能准确解析并重写,实现敏感数据的无缝加密与解密,保障了原有业务逻辑的完整性和报表功能的正常运行。
- 大规模加密策略管理能力: 面对“数百张表、上千字段”的加密需求,SphereEx控制台提供了高效的批量策略配置和模板化管理功能,使安全团队能够快速部署和审计全库的加密状态,将原本繁琐不堪的管理工作变得简单高效。
- 业务无侵入与透明性: “网关代理”模式确保了对现有业务的零干扰。应用程序无需感知加密过程,最大程度降低了实施风险,保障了核心金融业务的连续性和稳定性。
客户收益
核心成果:
- 100%合规性达成: 成功对亿级存量及增量客户数据完成加密,确保所有敏感信息在数据库中以密文形式存储,满足了国家及金融行业监管机构的合规审计要求。
- 实现业务零改造加密: 在未修改一行业务代码的前提下,完成了全系统数据加密上线,显著缩短了项目周期,避免了因代码改动可能引入的风险,实施成本降低超70%。
- 加密覆盖全面: 高效完成了对数百张业务表、上千个敏感字段的加密策略部署与管理,加密策略执行准确率100%。
- 兼容模式保障业务连续性:当复杂SQL在路由、改写或执行异常时,系统可自动识别并启用兼容方案,确保加密操作在复杂场景下稳定完成,全程无需人工干预,有效规避业务中断风险。
战略价值:
- 有效降低商业与法律风险: 从根本上杜绝了因数据泄露导致的企业声誉损失、客户诉讼及监管重罚等重大风险,保护了企业的核心资产。
- 保障业务敏捷性: 透明加密方案使得业务系统在获得安全能力的同时,保持了高度的灵活性和可扩展性,未来新增业务或字段可快速纳入加密体系,支撑业务快速发展。
- 提升安全运维效率: 集中化的管控平台改变了以往“人盯人”的粗放式数据安全管理模式,实现了策略的标准化、自动化管理,提升了整体安全运营水平。
- 树立行业安全标杆: 本项目的成功实施,为汽车金融行业在核心业务系统数据安全建设方面提供了最佳实践范例,增强了客户在行业内的领先形象。
