
客户介绍
客户介绍:
【某大型综合金融集团核心银行】作为中国金融业综合金融与科技创新的标杆银行,依托集团生态优势,已发展成为零售转型领先、科技能力突出的全国性商业银行。其服务覆盖个人金融、企业金融与资金同业等领域,管理资产规模超万亿,服务数百万对公客户与上亿个人客户。在此背景下,其核心业务系统每日需处理亿级交易数据,承载着海量客户资产、账户信息及敏感交易记录。这些数据的安全存储、高效处理与实时访问,直接关系到金融系统的稳定性、合规性及客户体验,对底层数据基础平台的可靠性、弹性与安全有着极高的要求。
应用介绍:
应用名称:银行核心业务系统
应用说明:系统涵盖核心账务、支付清算、客户服务、风险控制及技术平台,支撑全行存款信贷、资金结算、线上渠道和数据分析等关键业务,是业务连续与安全、高效运行的保障。
业务挑战
客户需求:
随着金融行业数字化转型的深入推进,该银行作为国内领先的综合性金融服务集团,其核心业务系统承载着海量高敏数据的存储、处理与流转。在《中华人民共和国数据安全法》《个人信息保护法》《金融行业密码应用指导意见》等法规政策驱动下,银行业对数据安全防护的要求日益严格,尤其在商用密码应用、敏感数据加密存储、分布式架构下数据分片管理等场景面临重大技术挑战。当前银行自研的VeXXX中间件平台虽然已具备了一定加密和分布式能力,但在实际应用中仍存在以下核心痛点:
核心痛点:
- SQL兼容性与开发效率低: 现有平台对MySQL、Oracle、OceanBase等异构数据库的SQL语法解析能力不足,尤其在复杂查询、分布式事务等场景下需大量人工适配,显著降低了开发效率。同时,缺乏对敏感数据的自动化识别与动态脱敏能力,难以满足金融数据安全合规要求。
- 数据加密体系不合规: 原有加密方案严重依赖数据库原生功能,未全面支持国密算法(SM2/SM3/SM4),不符合国家商用密码应用安全性评估标准。密钥管理分散,缺乏统一的生命周期管理和与硬件加密机(HSM)的集成,存在安全风险。
- 数据分片与查询性能瓶颈: 现有分片策略单一,导致数据分布不均,数据倾斜率超过15%,影响系统扩展性。跨分片查询效率低下,平均响应延迟超过500ms,无法满足高并发实时业务对性能的苛刻要求。
解决方案
方案概述:
本次方案基于银行原有的VeXXX中间件平台(基于ShardingSphere自研)进行深度增强,构建了一个三层解耦、集中管控的全新数据访问层基础平台。方案在保留平台稳定性的基础上,重点增强了其SQL解析能力、内置了合规的国密算法加密体系、并优化了智能分片与跨分片查询能力,形成了从业务需求到平台能力再到数据支撑的完整闭环,有效解决了客户在合规、性能与效率上的核心挑战。
架构图:
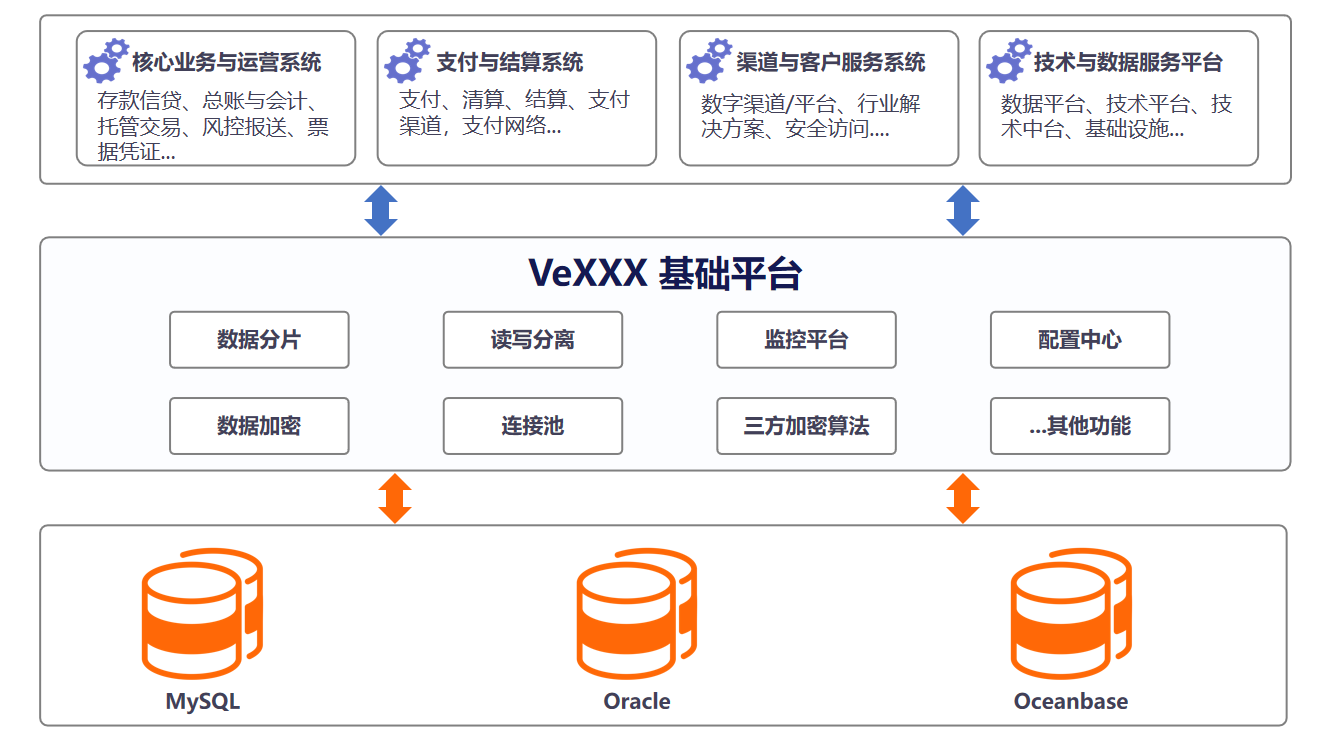
方案亮点
- 增强的SQL解析与治理能力: 提供强大的跨数据库SQL方言解析与优化能力,显著减少开发适配工作量,并内置敏感数据自动识别与动态脱敏功能,提升开发效率与合规性。
- 合规、统一的数据安全加密体系: 原生支持国密算法(SM2/SM3/SM4),并提供与硬件加密机(HSM)集成的统一密钥管理服务,实现密钥全生命周期管理,确保加密方案完全符合国家规范。
- 智能分片与高性能跨片查询: 引入弹性分片策略与优化算法,将数据倾斜率大幅降低至5%以下,支持线性扩展;通过分布式查询优化,将跨分片查询平均延迟降低至100ms以内。
- 密态数据运算支持: 在数据加密状态下,仍支持等值查询、LIKE模糊匹配、排序等密文计算操作,实现了安全与业务便利性的平衡。
客户收益
核心成果:
- 性能显著优化:通过深度测试与定制化优化,平台在核心业务场景下实现性能提升28%,内存消耗降低20%,有力支撑了高频交易场景。
- 运维效率提升:构建统一的数据库接入层,实现对多类型异构数据库的集中管理,运维复杂度降低约40%,系统可控性进一步增强。
- 安全合规达标:成功打造内嵌数据加密与访问控制的安全底座,实现关键敏感数据100%加密存储,全面满足金融级合规要求。
战略价值:
- 夯实信创基石:率先完成对OceanBase等信创数据库的深度适配,为全行技术架构的安全可控转型扫清障碍,赢得先机。
- 统一架构支撑:完成了数据访问层的基础性升级,打造了“集中、解耦、标准”的现代化数据架构,为业务快速创新提供了坚实基础。
- 增强业务韧性:大幅提升了数据平台的高可用性与抗压能力,有效保障了核心业务的连续性,提升了银行的市场竞争力与客户信任度。
