
客户介绍
客户介绍:
【某领先运动品牌零售商】作为中国领先的运动零售运营商,隶属于港股上市公司,业务涵盖运动鞋服的全渠道零售,是多个国际一线运动品牌在中国市场的核心战略合作伙伴。凭借覆盖全国数千家直营门店的庞大网络,公司服务着数千万的会员用户,年营业额达数百亿级别。会员销售贡献占比极高,凸显其深厚的用户运营基础。在业务持续扩张和数字化深化的背景下,公司核心业务数据的存储与流转安全,防范数据泄露与合规风险,已成为其技术建设的核心诉求与业务可持续发展的根本保障。
应用介绍:
应用名称:HR系统
应用说明:该系统是支撑企业高效运营的一体化数字平台,深度整合了组织人事、薪酬绩效、考勤及电子流程等核心模块,全面覆盖员工从入职到离职的全职业生命周期管理,系统中存储着大量员工身份信息、薪酬数据等高度敏感的信息。
业务挑战
客户需求:
随着数据安全法律法规的完善与执法力度加强,客户需对其HR系统中的所有敏感个人信息与薪酬数据进行最高等级的加密保护,并实现字段级的精细访问权限控制。核心需求是:在满足合规“硬指标”的同时,绝不能影响全国HR部门和员工日常使用系统的体验,也不能中断任何正在运行的复杂薪酬计算与报表流程。
核心痛点:
- 外采应用不可改造: 人力资源管理系统为外部采购,无应用程序源代码,无法通过传统的修改应用代码方式实现数据加密,技术手段受限。
- 字段级精准防护与控制: 系统内敏感字段众多,且业务上需要实现字段级的权限访问控制,传统数据库权限管理粒度粗,难以满足精细化安全需求。
- 改造风险与复杂性高: 系统中运行着大量支撑业务决策的复杂报表查询与存储过程,这些对象逻辑复杂、相互调用紧密。若采用常规的逐项SQL改造方式,将面临工作量大、实施周期长、兼容性风险高以及潜在的性能下降隐患。
解决方案
方案概述:
本方案基于SphereEx数据安全产品,为外采HR系统构建了一套全链路、无侵入的数据安全防护体系。方案采用“加密驱动+加密网关”的混合部署模式,在数据库访问层实现透明化数据加密与解密。业务人员通过HR系统进行操作时,数据以明文形式正常使用,全程无感知。数据库管理员则通过SphereEx提供的统一安全控制台,进行集中化、图形化的加密策略配置与密钥管理,无需改动任何业务代码或SQL语句,即可实现对核心数据的加密存储与安全访问控制。该架构有效平衡了安全与效率,在确保最高级别数据安全与合规的同时,保障了业务的连续性与稳定性。
架构图:
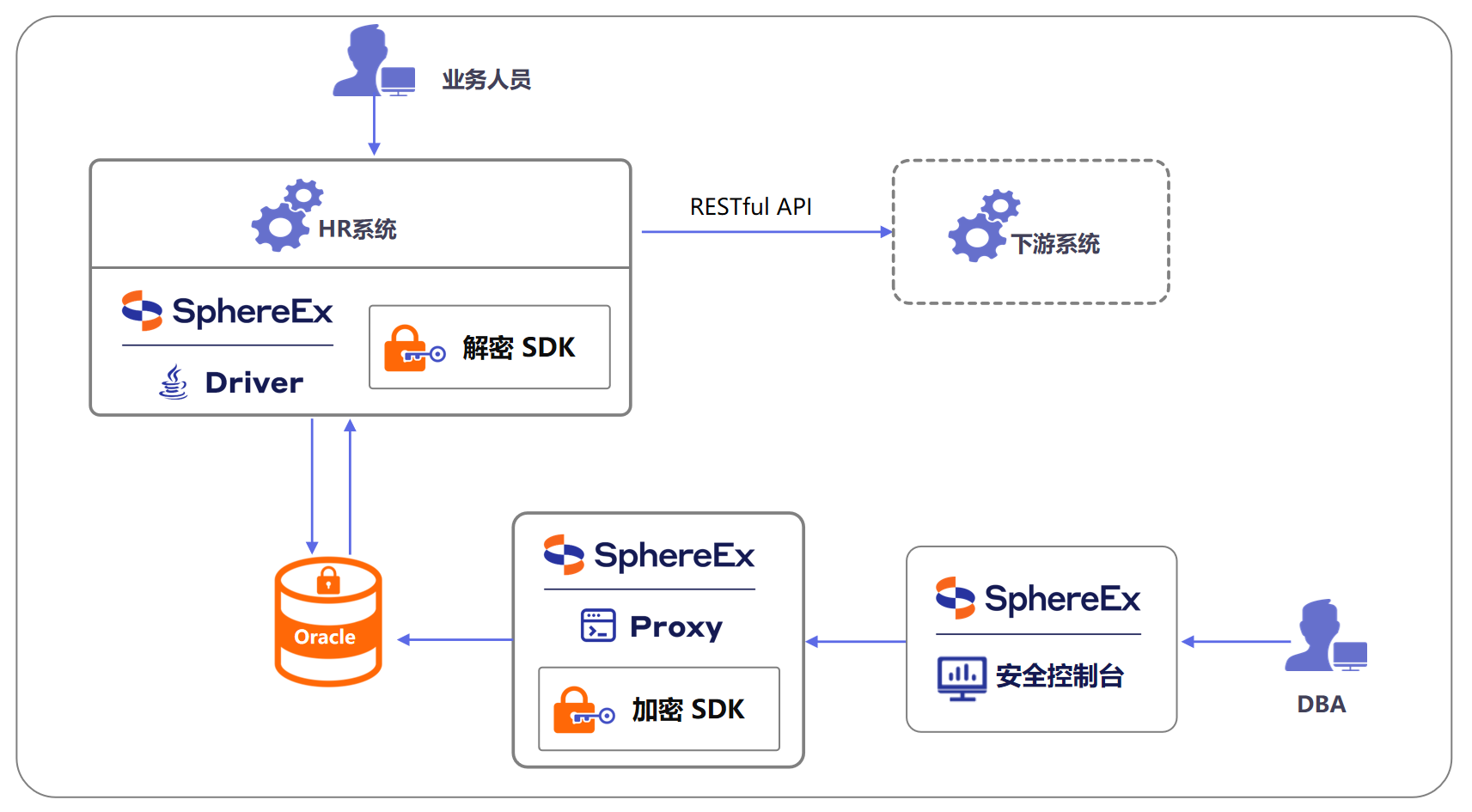
方案亮点
- 无侵入式透明加密: 通过集成数据安全驱动的技术手段,完美解决了外采应用因无源代码而无法改造的难题,实现了对业务的完全透明化,无需应用侧改动代码,极大降低了落地难度和风险。
- 字段级精细加密与授权: 提供字段级别的数据加密与访问授权能力,支持对单张表内的任意指定字段进行独立加密,在权限控制方面,可实现对库、表、列三级权限的精准匹配,有效防范越权访问。
- 存储过程复杂运算支持: 强大的密文运算能力,支持加密数据在数据库存储过程中进行等值查询、模糊查询等多种复杂运算,确保了加密后原有复杂报表和存储过程的逻辑正常运行,无需解密即可处理,兼顾了安全性与业务连续性。
客户收益
核心成果:
- 高效合规落地: 在不修改一行业务代码的情况下,快速完成了对HR系统核心敏感数据的加密改造,相比传统改造方式,实施效率提升超过70%。
- 风险显著降低: 实现了对千万级数据记录中核心敏感字段的加密保护,有效将潜在的数据泄露风险降至最低,并满足了《数据安全法》等法律法规的强制性合规要求。
- 业务无缝平滑: 加密过程对HR系统用户完全透明,保障了大量复杂报表和业务存储过程的正常运行,未出现任何兼容性问题,业务性能波动控制在5%以内,确保了业务操作的流畅体验。
战略价值:
- 构建可持续的安全架构: 本次项目为企业建立了一套可复制的数据安全保护范式,未来可快速扩展至其他外采或自研系统,形成了统一、可持续演进的数据安全基础设施。
- 建立可持续的数据安全运维能力:通过集中管理平台,客户IT和安全团队获得了对核心数据安全状态的可视化掌控能力和灵活的策略调整能力,为应对未来不断演变的合规要求构建了敏捷响应基础。
- 强化品牌信任与合规形象: 通过实施业界领先的数据安全方案,向员工、合作伙伴及资本市场展示了企业对数据安全和隐私保护的最高承诺,增强了品牌公信力,为上市公司合规审计提供了坚实保障。
