
业务挑战
该单位的业务数据需要通过互联网对外展示,在实现数据共享和公共数据资源开放的同时,需要确保敏感信息不被泄露。
方案亮点
不修改应用程序源代码,实现敏感信息加密和脱敏。
解决方案
本项目使用了 SphereEx 数据安全平台产品,在不修改应用程序源代码的前提下,对业务数据中的敏感信息加密,实现了业务数据在互联网上共享,同时保护敏感信息不被泄露。
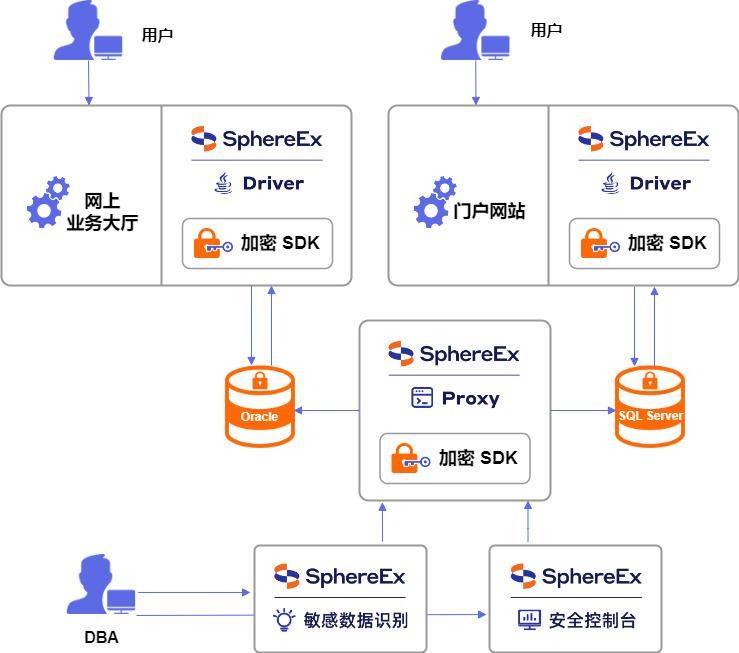
1. 数据加密
本项目使用SphereEx 数据加密技术对敏感数据进行加密,包含数据安全。数据加密是指通过特定的算法将原始数据(明文)转换为密文的过程,SphereEx 数据安全平台对数据库中的敏感数据进行加密处理,以防止数据泄露和非法访问。
通过 SphereEx 数据安全平台,用户可以快速完成数据加密,无需自行开发复杂的加密系统。
SphereEx 数据加密技术具有以下特点:
- 应用免改造:无需改造应用程序,快速实现数据安全合规改造。
- 零停机上线:业务系统无需停机,在线完成密文转换及密钥轮转。
- 安全可逃生:业务系统改造安全合规改造无风险,可回退。
- 行列级加密:加密范围灵活可控,支持行级、列级加密,安全程度高。
- 多种算法支持:支持 SM2、SM3、SM4 等国密算法,支持 AES 、DES 、FPE 、RSA 、RC4 、OPE 、MD5 、SHA256 等国际主流加密算法,支持自定义算法。
- 多种数据库支持:支持 MySQL、PostgreSQL、Oracle、AWS Aurora、OpenGauss、SQLServer、KingbaseES、达梦-DM8、GBase 8c、GaussDB、OceanBase、GoldenDB、Clickhouse、Doris、StarRocks、Hive、Presto等。
2. 数据脱敏
本项目使用SphereEx 数据脱敏技术,对敏感数据进行脱敏处理,避免敏感信息泄露。数据脱敏是对敏感数据进行脱敏处理,使其在不改变原始数据含义的前提下,降低或消除数据中的敏感信息,从而保护个人隐私和商业机密。
数据脱敏的目的:
- 保护隐私:保护个人隐私信息,如姓名、身份证号、电话号码等。
- 数据安全:防止企业敏感数据泄露。
- 合规性:满足法律法规对数据保护的要求。
SphereEx 数据安全平台针对不同行业、不同业务场景,对数据进行脱敏,避免数据在采集、传输、使用等环节中的暴露风险。平台内置丰富的脱敏算法,能够根据用户的数据脱敏需求,通过遮盖、替换等方式,对敏感数据进行脱敏展示和脱敏使用。
客户收益
公共数据资源开放的同时,确保敏感数据安全。
